For this question, refer to the HipLocal case study.
HipLocal's application uses Cloud Client Libraries to interact with Google Cloud. HipLocal needs to configure authentication and authorization in the Cloud Client Libraries to implement least privileged access for the application. What should they do?
HipLocal’s data science team wants to analyze user reviews.
How should they prepare the data?
For this question, refer to the HipLocal case study.
How should HipLocal increase their API development speed while continuing to provide the QA team with a stable testing environment that meets feature requirements?
For this question, refer to the HipLocal case study.
HipLocal is expanding into new locations. They must capture additional data each time the application is launched in a new European country. This is causing delays in the development process due to constant schema changes and a lack of environments for conducting testing on the application changes. How should they resolve the issue while meeting the business requirements?
HipLocal wants to improve the resilience of their MySQL deployment, while also meeting their business and technical requirements.
Which configuration should they choose?
For this question, refer to the HipLocal case study.
Which Google Cloud product addresses HipLocal’s business requirements for service level indicators and objectives?
For this question, refer to the HipLocal case study.
How should HipLocal redesign their architecture to ensure that the application scales to support a large increase in users?
Your service adds text to images that it reads from Cloud Storage. During busy times of the year, requests to
Cloud Storage fail with an HTTP 429 "Too Many Requests" status code.
How should you handle this error?
You are supporting a business-critical application in production deployed on Cloud Run. The application is reporting HTTP 500 errors that are affecting the usability of the application. You want to be alerted when the number of errors exceeds 15% of the requests within a specific time window. What should you do?
You are building a CI/CD pipeline that consists of a version control system, Cloud Build, and Container Registry. Each time a new tag is pushed to the repository, a Cloud Build job is triggered, which runs unit tests on the new code builds a new Docker container image, and pushes it into Container Registry. The last step of your pipeline should deploy the new container to your production Google Kubernetes Engine (GKE) cluster. You need to select a tool and deployment strategy that meets the following requirements:
• Zero downtime is incurred
• Testing is fully automated
• Allows for testing before being rolled out to users
• Can quickly rollback if needed
What should you do?
You are using Cloud Run to host a web application. You need to securely obtain the application project ID and region where the application is running and display this information to users. You want to use the most performant approach. What should you do?
Your teammate has asked you to review the code below. Its purpose is to efficiently add a large number of small rows to a BigQuery table.

Which improvement should you suggest your teammate make?
You are building an API that will be used by Android and iOS apps The API must:
• Support HTTPs
• Minimize bandwidth cost
• Integrate easily with mobile apps
Which API architecture should you use?
You are creating an App Engine application that writes a file to any user's Google Drive.
How should the application authenticate to the Google Drive API?
Your company has created an application that uploads a report to a Cloud Storage bucket. When the report is uploaded to the bucket, you want to publish a message to a Cloud Pub/Sub topic. You want to implement a solution that will take a small amount to effort to implement. What should you do?
Your team detected a spike of errors in an application running on Cloud Run in your production project. The application is configured to read messages from Pub/Sub topic A, process the messages, and write the messages to topic B. You want to conduct tests to identify the cause of the errors. You can use a set of mock messages for testing. What should you do?
Your website is deployed on Compute Engine. Your marketing team wants to test conversion rates between 3
different website designs.
Which approach should you use?
HipLocal is configuring their access controls.
Which firewall configuration should they implement?
In order for HipLocal to store application state and meet their stated business requirements, which database service should they migrate to?
HipLocal wants to reduce the number of on-call engineers and eliminate manual scaling.
Which two services should they choose? (Choose two.)
You are parsing a log file that contains three columns: a timestamp, an account number (a string), and a
transaction amount (a number). You want to calculate the sum of all transaction amounts for each unique
account number efficiently.
Which data structure should you use?
You are creating a Google Kubernetes Engine (GKE) cluster and run this command:
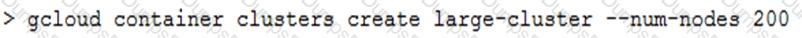
The command fails with the error:

You want to resolve the issue. What should you do?
Your code is running on Cloud Functions in project A. It is supposed to write an object in a Cloud Storage
bucket owned by project B. However, the write call is failing with the error "403 Forbidden".
What should you do to correct the problem?
You have deployed an HTTP(s) Load Balancer with the gcloud commands shown below.
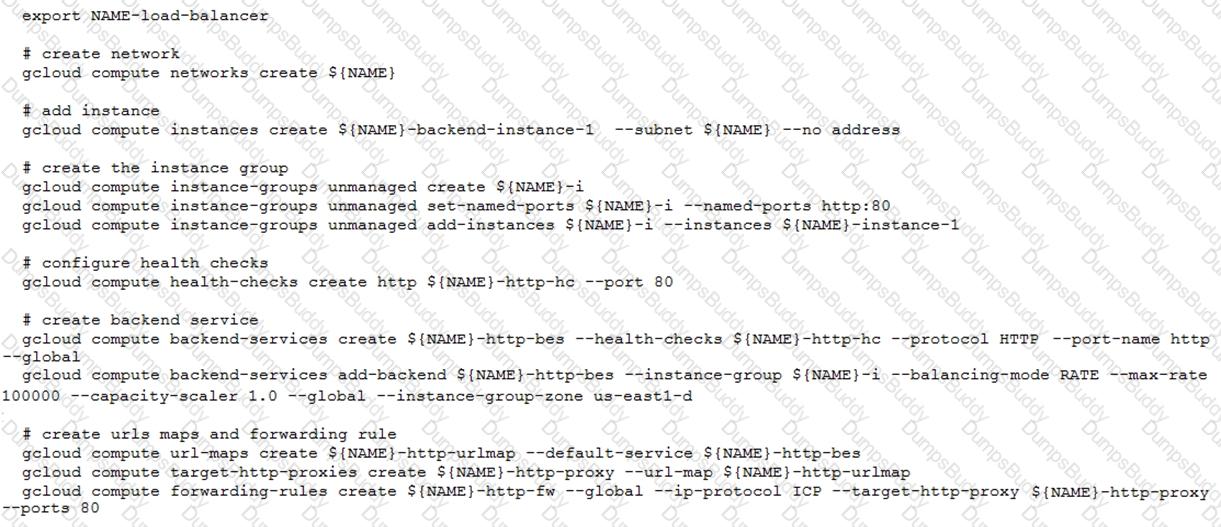
Health checks to port 80 on the Compute Engine virtual machine instance are failing and no traffic is sent to your instances. You want to resolve the problem.
Which commands should you run?
You want to create “fully baked” or “golden” Compute Engine images for your application. You need to bootstrap your application to connect to the appropriate database according to the environment the application is running on (test, staging, production). What should you do?
You are deploying a Python application to Cloud Run using Cloud Build. The Cloud Build pipeline is shown below:

You want to optimize deployment times and avoid unnecessary steps What should you do?
You are developing an internal application that will allow employees to organize community events within your company. You deployed your application on a single Compute Engine instance. Your company uses Google Workspace (formerly G Suite), and you need to ensure that the company employees can authenticate to the application from anywhere. What should you do?
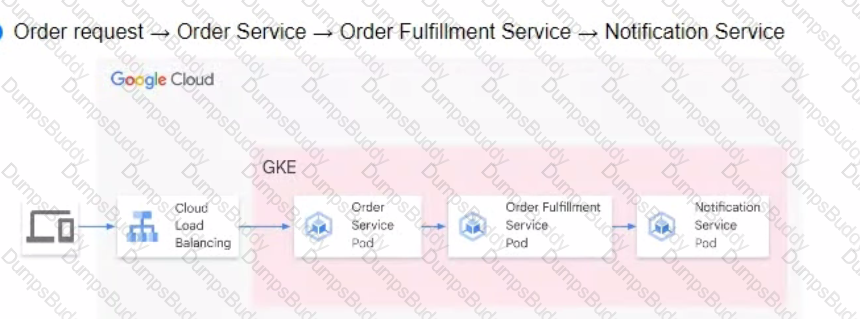
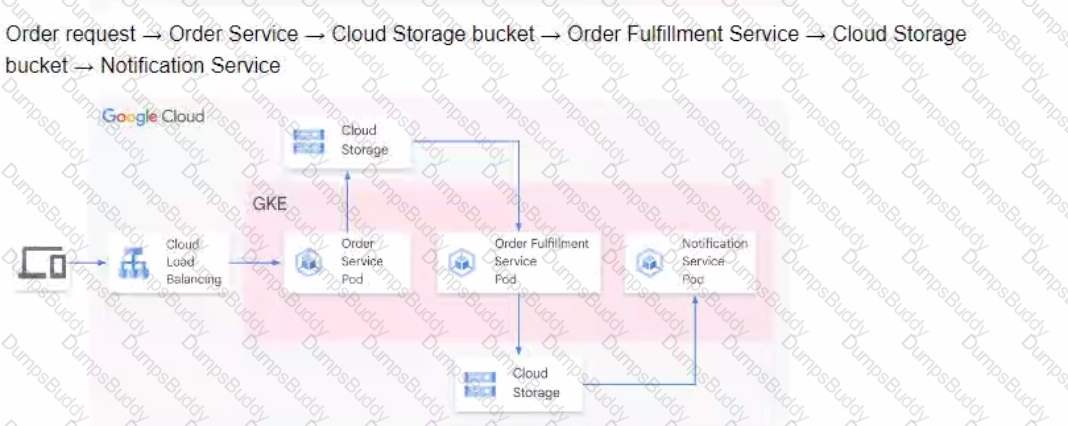
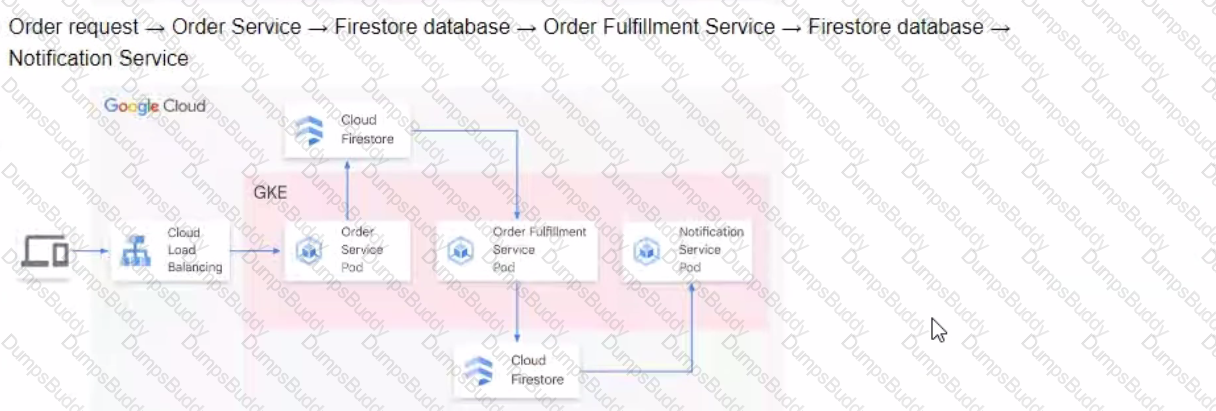
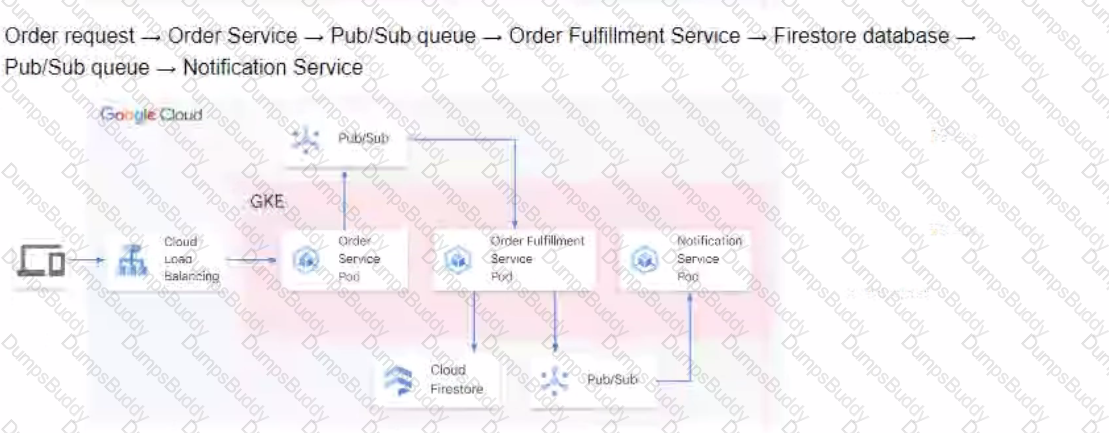
You are developing a flower ordering application Currently you have three microservices.
• Order Service (receives the orders).
• Order Fulfillment Service (processes the orders).
• Notification Service (notifies the customer when the order is filled).
You need to determine how the services will communicate with each other. You want incoming orders to be processed quickly and you need to collect order information for fulfillment. You also want to make sure orders are not lost between your services and are able to communicate asynchronously. How should the requests be processed?
Your application performs well when tested locally, but it runs significantly slower when you deploy it to App Engine standard environment. You want to diagnose the problem. What should you do?
Your company has a BigQuery dataset named "Master" that keeps information about employee travel and
expenses. This information is organized by employee department. That means employees should only be able
to view information for their department. You want to apply a security framework to enforce this requirement
with the minimum number of steps.
What should you do?
You are a developer working with the CI/CD team to troubleshoot a new feature that your team introduced. The CI/CD team used HashiCorp Packer to create a new Compute Engine image from your development branch. The image was successfully built, but is not booting up. You need to investigate the issue with the CI/CD team. What should you do?
You are designing an application that consists of several microservices. Each microservice has its own RESTful API and will be deployed as a separate Kubernetes Service. You want to ensure that the consumers of these APIs aren't impacted when there is a change to your API, and also ensure that third-party systems aren't interrupted when new versions of the API are released. How should you configure the connection to the application following Google-recommended best practices?
You deployed a new application to Google Kubernetes Engine and are experiencing some performance degradation. Your logs are being written to Cloud Logging, and you are using a Prometheus sidecar model for capturing metrics. You need to correlate the metrics and data from the logs to troubleshoot the performance issue and send real-time alerts while minimizing costs. What should you do?
You are designing an application that will subscribe to and receive messages from a single Pub/Sub topic and insert corresponding rows into a database. Your application runs on Linux and leverages preemptible virtual machines to reduce costs. You need to create a shutdown script that will initiate a graceful shutdown. What should you do?
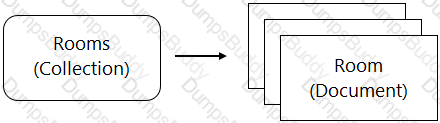
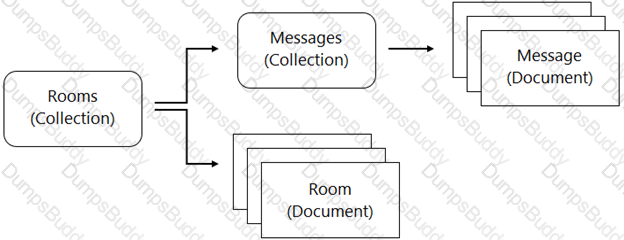
You are designing a chat room application that will host multiple rooms and retain the message history for each room. You have selected Firestore as your database. How should you represent the data in Firestore?
Create a collection for the rooms. For each room, create a document that lists the contents of the messages
Create a collection for the rooms. For each room, create a collection that contains a document for each message

Create a collection for the rooms. For each room, create a document that contains a collection for documents, each of which contains a message.

Create a collection for the rooms, and create a document for each room. Create a separate collection for messages, with one document per message. Each room’s document contains a list of references to the messages.
Your company stores their source code in a Cloud Source Repositories repository. Your company wants to build and test their code on each source code commit to the repository and requires a solution that is managed and has minimal operations overhead.
Which method should they use?
You plan to deploy a new application revision with a Deployment resource to Google Kubernetes Engine (GKE) in production. The container might not work correctly. You want to minimize risk in case there are issues after deploying the revision. You want to follow Google-recommended best practices. What should you do?
You have been tasked with planning the migration of your company’s application from on-premises to Google Cloud. Your company’s monolithic application is an ecommerce website. The application will be migrated to microservices deployed on Google Cloud in stages. The majority of your company’s revenue is generated through online sales, so it is important to minimize risk during the migration. You need to prioritize features and select the first functionality to migrate. What should you do?
You have two tables in an ANSI-SQL compliant database with identical columns that you need to quickly
combine into a single table, removing duplicate rows from the result set.
What should you do?
You work for a web development team at a small startup. Your team is developing a Node.js application using Google Cloud services, including Cloud Storage and Cloud Build. The team uses a Git repository for version control. Your manager calls you over the weekend and instructs you to make an emergency update to one of the company’s websites, and you’re the only developer available. You need to access Google Cloud to make the update, but you don’t have your work laptop. You are not allowed to store source code locally on a non-corporate computer. How should you set up your developer environment?
Your team develops services that run on Google Cloud. You need to build a data processing service and will use Cloud Functions. The data to be processed by the function is sensitive. You need to ensure that invocations can only happen from authorized services and follow Google-recommended best practices for securing functions. What should you do?
Your company’s development teams want to use various open source operating systems in their Docker builds. When images are created in published containers in your company’s environment, you need to scan them for Common Vulnerabilities and Exposures (CVEs). The scanning process must not impact software development agility. You want to use managed services where possible. What should you do?
You are a developer at a large organization Your team uses Git for source code management (SCM). You want to ensure that your team follows Google-recommended best practices to manage code to drive higher rates of software delivery. Which SCM process should your team use?
You are developing an application that consists of several microservices running in a Google Kubernetes Engine cluster. One microservice needs to connect to a third-party database running on-premises. You need to store credentials to the database and ensure that these credentials can be rotated while following security best practices. What should you do?
Your organization has recently begun an initiative to replatform their legacy applications onto Google Kubernetes Engine. You need to decompose a monolithic application into microservices. Multiple instances have read and write access to a configuration file, which is stored on a shared file system. You want to minimize the effort required to manage this transition, and you want to avoid rewriting the application code. What should you do?
You are developing an application hosted on Google Cloud that uses a MySQL relational database schema. The application will have a large volume of reads and writes to the database and will require backups and ongoing capacity planning. Your team does not have time to fully manage the database but can take on small administrative tasks. How should you host the database?
You want to re-architect a monolithic application so that it follows a microservices model. You want to
accomplish this efficiently while minimizing the impact of this change to the business.
Which approach should you take?
You recently deployed your application in Google Kubernetes Engine, and now need to release a new version of your application. You need the ability to instantly roll back to the previous version in case there are issues with the new version. Which deployment model should you use?
You have an analytics application that runs hundreds of queries on BigQuery every few minutes using BigQuery API. You want to find out how much time these queries take to execute. What should you do?
Your team is setting up a build pipeline for an application that will run in Google Kubernetes Engine (GKE). For security reasons, you only want images produced by the pipeline to be deployed to your GKE cluster. Which combination of Google Cloud services should you use?
HipLocal's.net-based auth service fails under intermittent load.
What should they do?
For this question, refer to the HipLocal case study.
A recent security audit discovers that HipLocal’s database credentials for their Compute Engine-hosted MySQL databases are stored in plain text on persistent disks. HipLocal needs to reduce the risk of these credentials being stolen. What should they do?
In order to meet their business requirements, how should HipLocal store their application state?
HipLocal has connected their Hadoop infrastructure to GCP using Cloud Interconnect in order to query data stored on persistent disks.
Which IP strategy should they use?
For this question refer to the HipLocal case study.
HipLocal wants to reduce the latency of their services for users in global locations. They have created read replicas of their database in locations where their users reside and configured their service to read traffic using those replicas. How should they further reduce latency for all database interactions with the least amount of effort?


TESTED 21 May 2025
