DP-750 Implementing Data Engineering Solutions Using Azure Databricks Questions and Answers
You have an Azure Databticks workspace that contains an all-purpose compute cluster named Cluster1. Cluser1 is used for
interactive development.
You need to configure Cluster1 to meet the following requirements:
• Automatically add and remove worker nodes based on workload demand
• Automatically shut down when the cluster has been idle for a specific period.
What should you configure for each requirement? To answer, drag the appropriate options to the correct requirements. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.


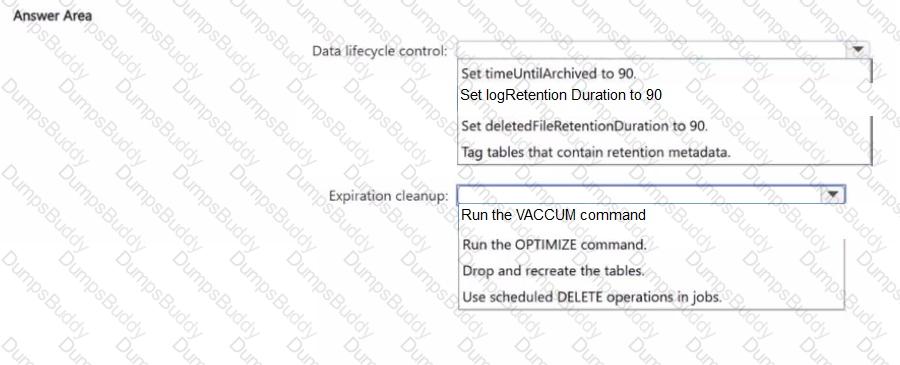
You have an Azure Databricks workspace that contains a Delta table named Table 1. Table 1 has accumulated obsolete files.
You need to reduce storage costs. The solution must preserve 30 days of time travel history. Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
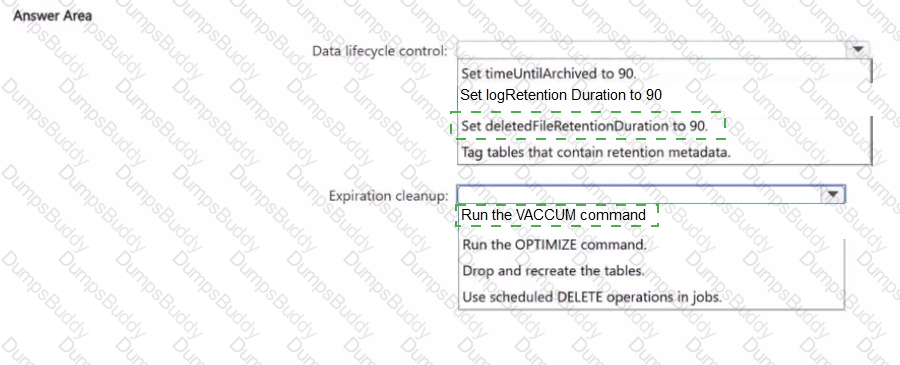
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You need to implement a data lifecycle and expiration solution that meets the following requirements
• Transaction logs and deleted data files that are older than 90 days must be removed from Delta tables to reclaim storage.
• All the tables must remain available for querying during the cleanup process.
• Administrative effort must be minimized
What should you do for each requirement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
You need to complete the PySpark code for the Spark Structured Streaming pipelines. The solution must meet the data ingestion and processing requirements.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


Which ingestion option should you recommend for each data source? To answer, drag the appropriate options to the correct data sources. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


You need to develop the task logic for a new job in Lakeflow Jobs that processes telemetry data.
Each task must contain only the appropriate logic for its step in the pipeline. The solution must support the planned changes and meet the data ingestion and processing requirements.
What should you do?
Which SCD type should you use to support the planned data modeling changes? To answer, drag the appropriate types to the correct issues. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


You have an Azure Databricks workspace named Workspace1 that contains a lakehouse and is enabled for Unity Catalog.
You have a connection to a Microsoft SQL Server database named DB1.
You need to expose the schemas and tables of DB1 to meet the following requirements:
• The schemas and tables can be queried in Databricks.
• The schemas and tables appear alongside other Unity Catalog objects.
• The data is NOT copied into Databricks-managed storage.
Solution: You create a Databricks access connector.
Does this meet the goal?
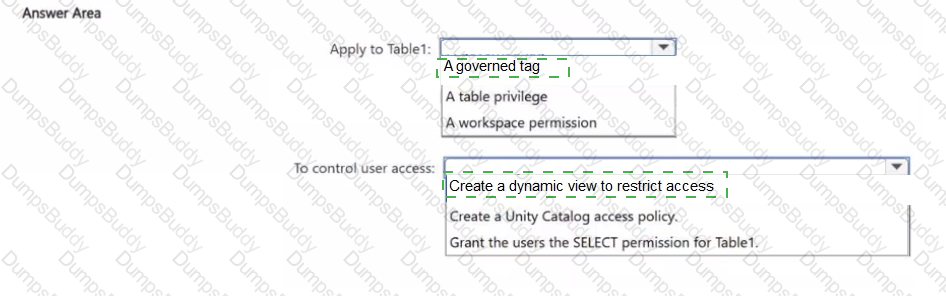
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a catalog named CatalogV Catalog1 contains a schema named Schema! and a table named Table1.
You need to ensure that access to the data in Table1 is controlled by using attribute based access control (ABAC).
What should you apply to Table1, and how should you control access for users? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You have an Azure Databricks workspace that is enabled for Unity Catalog
You have an Apache Spark Structured Streaming job that writes data to a Delta table.
After the cluster restarts, the streaming job reprocesses previously ingested data
You need to prevent the streaming job from reprocessing the data after the cluster restarts.
What should you do?
PDF + Testing Engine

Testing Engine
PDF (Q&A)

