Databricks-Certified-Professional-Data-Engineer Databricks Certified Data Engineer Professional Exam Questions and Answers
A data engineer wants to join a stream of advertisement impressions (when an ad was shown) with another stream of user clicks on advertisements to correlate when impression led to monitizable clicks.

Which solution would improve the performance?
A)
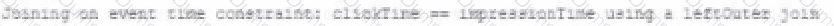
B)
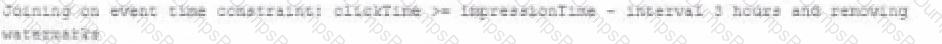
C)
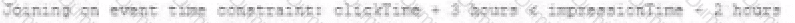
D)

The security team is exploring whether or not the Databricks secrets module can be leveraged for connecting to an external database.
After testing the code with all Python variables being defined with strings, they upload the password to the secrets module and configure the correct permissions for the currently active user. They then modify their code to the following (leaving all other variables unchanged).

Which statement describes what will happen when the above code is executed?
The data engineer team is configuring environment for development testing, and production before beginning migration on a new data pipeline. The team requires extensive testing on both the code and data resulting from code execution, and the team want to develop and test against similar production data as possible.
A junior data engineer suggests that production data can be mounted to the development testing environments, allowing pre production code to execute against production data. Because all users have
Admin privileges in the development environment, the junior data engineer has offered to configure permissions and mount this data for the team.
Which statement captures best practices for this situation?
Spill occurs as a result of executing various wide transformations. However, diagnosing spill requires one to proactively look for key indicators.
Where in the Spark UI are two of the primary indicators that a partition is spilling to disk?
A user new to Databricks is trying to troubleshoot long execution times for some pipeline logic they are working on. Presently, the user is executing code cell-by-cell, using display() calls to confirm code is producing the logically correct results as new transformations are added to an operation. To get a measure of average time to execute, the user is running each cell multiple times interactively.
Which of the following adjustments will get a more accurate measure of how code is likely to perform in production?
An organization processes customer data from web and mobile applications. Data includes names, emails, phone numbers, and location history. Data arrives both as batch files (from SFTP daily) and streaming JSON events (from Kafka in real-time).
To comply with data privacy policies, the following requirements must be met:
Personally Identifiable Information (PII) such as email, phone number, and IP address must be masked or anonymized before storage.
Both batch and streaming pipelines must apply consistent PII handling.
Masking logic must be auditable and reproducible.
The masked data must remain usable for downstream analytics.
How should the data engineer design a compliant data pipeline on Databricks that supports both batch and streaming modes, applies data masking to PII, and maintains traceability for audits?
Which statement regarding stream-static joins and static Delta tables is correct?
To identify the top users consuming compute resources, a data engineering team needs to monitor usage within their Databricks workspace for better resource utilization and cost control. The team decided to use Databricks system tables, available under the System catalog in Unity Catalog, to gain detailed visibility into workspace activity.
Which SQL query should the team run from the System catalog to achieve this?
The data engineer team has been tasked with configured connections to an external database that does not have a supported native connector with Databricks. The external database already has data security configured by group membership. These groups map directly to user group already created in Databricks that represent various teams within the company.
A new login credential has been created for each group in the external database. The Databricks Utilities Secrets module will be used to make these credentials available to Databricks users.
Assuming that all the credentials are configured correctly on the external database and group membership is properly configured on Databricks, which statement describes how teams can be granted the minimum necessary access to using these credentials?
A platform engineer is creating catalogs and schemas for the development team to use.
The engineer has created an initial catalog, catalog_A, and initial schema, schema_A. The engineer has also granted USE CATALOG, USE
SCHEMA, and CREATE TABLE to the development team so that the engineer can begin populating the schema with new tables.
Despite being owner of the catalog and schema, the engineer noticed that they do not have access to the underlying tables in Schema_A.
What explains the engineer ' s lack of access to the underlying tables?
Which distribution does Databricks support for installing custom Python code packages?
Where in the Spark UI can one diagnose a performance problem induced by not leveraging predicate push-down?
A data engineer, while designing a Pandas UDF to process financial time-series data with complex calculations that require maintaining state across rows within each stock symbol group, must ensure the function is efficient and scalable. Which approach will solve the problem with minimum overhead while preserving data integrity?
A Spark job is taking longer than expected. Using the Spark UI, a data engineer notes that the Min, Median, and Max Durations for tasks in a particular stage show the minimum and median time to complete a task as roughly the same, but the max duration for a task to be roughly 100 times as long as the minimum.
Which situation is causing increased duration of the overall job?
A data engineer is running a groupBy aggregation on a massive user activity log grouped by user_id. A few users have millions of records, causing task skew and long runtimes.
Which technique will fix the skew in this aggregation?
A junior data engineer seeks to leverage Delta Lake ' s Change Data Feed functionality to create a Type 1 table representing all of the values that have ever been valid for all rows in a bronze table created with the property delta.enableChangeDataFeed = true . They plan to execute the following code as a daily job:
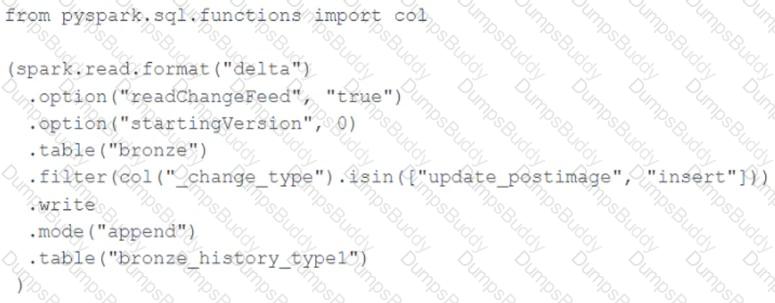
Which statement describes the execution and results of running the above query multiple times?
A data engineering team is setting up deployment automation. To deploy workspace assets remotely using the Databricks CLI command, they must configure it with proper authentication.
Which authentication approach will provide the highest level of security ?
A table is registered with the following code:
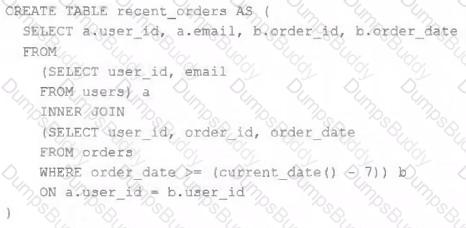
Both users and orders are Delta Lake tables. Which statement describes the results of querying recent_orders ?
The following table consists of items found in user carts within an e-commerce website.

The following MERGE statement is used to update this table using an updates view, with schema evaluation enabled on this table.

How would the following update be handled?
The business intelligence team has a dashboard configured to track various summary metrics for retail stories. This includes total sales for the previous day alongside totals and averages for a variety of time periods. The fields required to populate this dashboard have the following schema:

For Demand forecasting, the Lakehouse contains a validated table of all itemized sales updated incrementally in near real-time. This table named products_per_order, includes the following fields:

Because reporting on long-term sales trends is less volatile, analysts using the new dashboard only require data to be refreshed once daily. Because the dashboard will be queried interactively by many users throughout a normal business day, it should return results quickly and reduce total compute associated with each materialization.
Which solution meets the expectations of the end users while controlling and limiting possible costs?
A distributed team of data analysts share computing resources on an interactive cluster with autoscaling configured. In order to better manage costs and query throughput, the workspace administrator is hoping to evaluate whether cluster upscaling is caused by many concurrent users or resource-intensive queries.
In which location can one review the timeline for cluster resizing events?
A data engineer has created a transactions Delta table on Databricks that should be used by the analytics team. The analytics team wants to use the table with another tool that requires Apache Iceberg format.
What should the data engineer do?
The data governance team is reviewing user for deleting records for compliance with GDPR. The following logic has been implemented to propagate deleted requests from the user_lookup table to the user aggregate table.

Assuming that user_id is a unique identifying key and that all users have requested deletion have been removed from the user_lookup table, which statement describes whether successfully executing the above logic guarantees that the records to be deleted from the user_aggregates table are no longer accessible and why?
A Databricks job has been configured with 3 tasks, each of which is a Databricks notebook. Task A does not depend on other tasks. Tasks B and C run in parallel, with each having a serial dependency on task A.
If tasks A and B complete successfully but task C fails during a scheduled run, which statement describes the resulting state?
A data engineer is using Auto Loader to read incoming JSON data as it arrives. They have configured Auto Loader to quarantine invalid JSON records but notice that over time, some records are being quarantined even though they are well-formed JSON .
The code snippet is:
df = (spark.readStream
.format( " cloudFiles " )
.option( " cloudFiles.format " , " json " )
.option( " badRecordsPath " , " /tmp/somewhere/badRecordsPath " )
.schema( " a int, b int " )
.load( " /Volumes/catalog/schema/raw_data/ " ))
What is the cause of the missing data?
A workspace admin has created a new catalog called finance_data and wants to delegate permission management to a finance team lead without giving them full admin rights.
Which privilege should be granted to the finance team lead?
A data engineer has configured their Databricks Asset Bundle with multiple targets in databricks.yml and deployed it to the production workspace. Now, to validate the deployment, they need to invoke a job named my_project_job specifically within the prod target context. Assuming the job is already deployed, they need to trigger its execution while ensuring the target-specific configuration is respected.
Which command will trigger the job execution?
The data architect has decided that once data has been ingested from external sources into the
Databricks Lakehouse, table access controls will be leveraged to manage permissions for all production tables and views.
The following logic was executed to grant privileges for interactive queries on a production database to the core engineering group.
GRANT USAGE ON DATABASE prod TO eng;
GRANT SELECT ON DATABASE prod TO eng;
Assuming these are the only privileges that have been granted to the eng group and that these users are not workspace administrators, which statement describes their privileges?
An hourly batch job is configured to ingest data files from a cloud object storage container where each batch represent all records produced by the source system in a given hour. The batch job to process these records into the Lakehouse is sufficiently delayed to ensure no late-arriving data is missed. The user_id field represents a unique key for the data, which has the following schema:
user_id BIGINT, username STRING, user_utc STRING, user_region STRING, last_login BIGINT, auto_pay BOOLEAN, last_updated BIGINT
New records are all ingested into a table named account_history which maintains a full record of all data in the same schema as the source. The next table in the system is named account_current and is implemented as a Type 1 table representing the most recent value for each unique user_id .
Assuming there are millions of user accounts and tens of thousands of records processed hourly, which implementation can be used to efficiently update the described account_current table as part of each hourly batch job?
A Delta Lake table representing metadata about content from user has the following schema:
user_id LONG, post_text STRING, post_id STRING, longitude FLOAT, latitude FLOAT, post_time TIMESTAMP, date DATE
Based on the above schema, which column is a good candidate for partitioning the Delta Table?
A data engineer is designing a Lakeflow Spark Declarative Pipeline to process streaming order data. The pipeline uses Auto Loader to ingest data and must enforce data quality by ensuring customer_id is not null and amount is greater than zero. Invalid records should be dropped. Which Lakeflow Spark Declarative Pipelines configuration implements this requirement using Python?
A data engineer is using Lakeflow Declarative Pipelines Expectations feature to track the data quality of their incoming sensor data. Periodically, sensors send bad readings that are out of range, and they are currently flagging those rows with a warning and writing them to the silver table along with the good data. They’ve been given a new requirement – the bad rows need to be quarantined in a separate quarantine table and no longer included in the silver table.
This is the existing code for their silver table:
@dlt.table
@dlt.expect( " valid_sensor_reading " , " reading < 120 " )
def silver_sensor_readings():
return spark.readStream.table( " bronze_sensor_readings " )
What code will satisfy the requirements?
A facilities-monitoring team is building a near-real-time PowerBI dashboard off the Delta table device_readings:
Columns:
device_id (STRING, unique sensor ID)
event_ts (TIMESTAMP, ingestion timestamp UTC)
temperature_c (DOUBLE, temperature in °C)
Requirement:
For each sensor, generate one row per non-overlapping 5-minute interval , offset by 2 minutes (e.g., 00:02–00:07, 00:07–00:12, …).
Each row must include interval start, interval end, and average temperature in that slice.
Downstream BI tools (e.g., Power BI) must use the interval timestamps to plot time-series bars.
Options:
A query is taking too long to run. After investigating the Spark UI, the data engineer discovered a significant amount of disk spill . The compute instance being used has a core-to-memory ratio of 1:2.
What are the two steps the data engineer should take to minimize spillage? (Choose 2 answers)
Which statement describes the default execution mode for Databricks Auto Loader?
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.
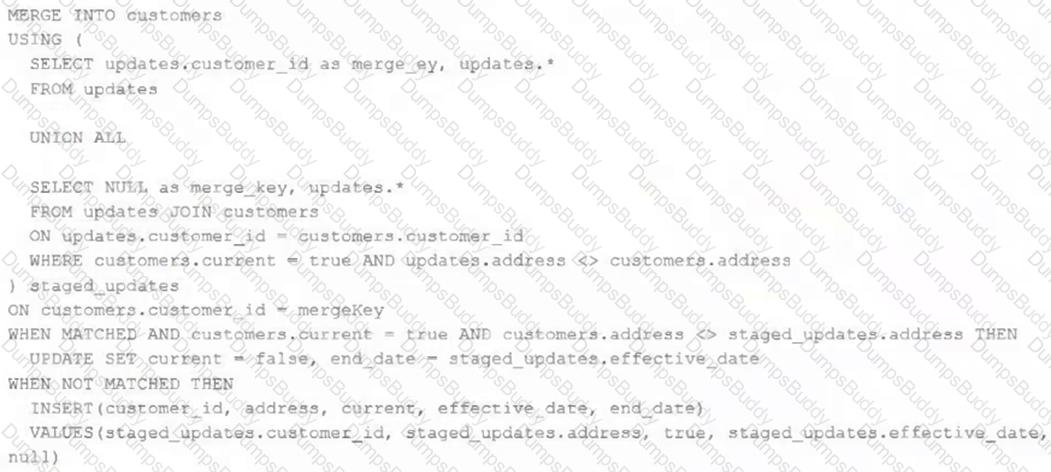
Which statement describes this implementation?
An upstream source writes Parquet data as hourly batches to directories named with the current date. A nightly batch job runs the following code to ingest all data from the previous day as indicated by the date variable:
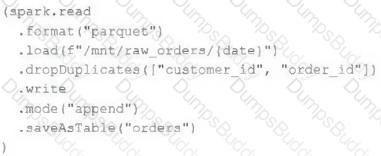
Assume that the fields customer_id and order_id serve as a composite key to uniquely identify each order.
If the upstream system is known to occasionally produce duplicate entries for a single order hours apart, which statement is correct?
A table named user_ltv is being used to create a view that will be used by data analysis on various teams. Users in the workspace are configured into groups, which are used for setting up data access using ACLs.
The user_ltv table has the following schema:

An analyze who is not a member of the auditing group executing the following query:

Which result will be returned by this query?
A data organization has adopted Delta Sharing to securely distribute curated datasets from a Unity Catalog-enabled workspace . The data engineering team shares large Delta tables internally via Databricks-to-Databricks and externally via Open Sharing for aggregated reports. While testing, they encounter challenges related to access control, data update visibility, and shareable object types.
What is a limitation of the Delta Sharing protocol or implementation when used with Databricks-to-Databricks or Open Sharing?
The data governance team is reviewing code used for deleting records for compliance with GDPR. They note the following logic is used to delete records from the Delta Lake table named users .

Assuming that user_id is a unique identifying key and that delete_requests contains all users that have requested deletion, which statement describes whether successfully executing the above logic guarantees that the records to be deleted are no longer accessible and why?
The data science team has created and logged a production model using MLflow. The following code correctly imports and applies the production model to output the predictions as a new DataFrame named preds with the schema " customer_id LONG, predictions DOUBLE, date DATE " .
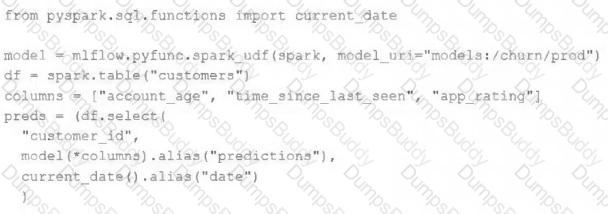
The data science team would like predictions saved to a Delta Lake table with the ability to compare all predictions across time. Churn predictions will be made at most once per day.
Which code block accomplishes this task while minimizing potential compute costs?
Options:
preds.write.mode( " append " ).saveAsTable( " churn_preds " )
preds.write.format( " delta " ).save( " /preds/churn_preds " )
C)

D)

E)

Option A
Option B
Option C
Option D
Option E
A data engineer is designing a Lakeflow Declarative Pipeline to process streaming order data. The pipeline uses Auto Loader to ingest data and must enforce data quality by ensuring customer_id and amount are greater than zero. Invalid records should be dropped.
Which Lakeflow Declarative Pipelines configurations implement this requirement using Python?
A data engineer deploys a multi-task Databricks job that orchestrates three notebooks. One task intermittently fails with Exit Code 1 but succeeds on retry. The engineer needs to collect detailed logs for the failing attempts, including stdout/stderr and cluster lifecycle context, and share them with the platform team.
What steps the data engineer needs to follow using built-in tools?
A company has a task management system that tracks the most recent status of tasks. The system takes task events as input and processes events in near real-time using Lakeflow Declarative Pipelines. A new task event is ingested into the system when a task is created or the task status is changed. Lakeflow Declarative Pipelines provides a streaming table (tasks_status) for BI users to query.
The table represents the latest status of all tasks and includes 5 columns:
task_id (unique for each task)
task_name
task_owner
task_status
task_event_time
The table enables three properties: deletion vectors, row tracking, and change data feed (CDF).
A data engineer is asked to create a new Lakeflow Declarative Pipeline to enrich the tasks_status table in near real-time by adding one additional column representing task_owner’s department, which can be looked up from a static dimension table (employee).
How should this enrichment be implemented?
A data team is automating a daily multi-task ETL pipeline in Databricks. The pipeline includes a notebook for ingesting raw data, a Python wheel task for data transformation, and a SQL query to update aggregates. They want to trigger the pipeline programmatically and see previous runs in the GUI. They need to ensure tasks are retried on failure and stakeholders are notified by email if any task fails.
Which two approaches will meet these requirements? (Choose 2 answers)
A Databricks SQL dashboard has been configured to monitor the total number of records present in a collection of Delta Lake tables using the following query pattern:
SELECT COUNT (*) FROM table -
Which of the following describes how results are generated each time the dashboard is updated?
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df . The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Events are recorded once per minute per device.
Streaming DataFrame df has the following schema:
" device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT "
Code block:

Choose the response that correctly fills in the blank within the code block to complete this task.
A data engineer wants to automate job monitoring and recovery in Databricks using the Jobs API. They need to list all jobs, identify a failed job, and rerun it.
Which sequence of API actions should the data engineer perform?
The data science team has created and logged a production using MLFlow. The model accepts a list of column names and returns a new column of type DOUBLE.
The following code correctly imports the production model, load the customer table containing the customer_id key column into a Dataframe, and defines the feature columns needed for the model.

Which code block will output DataFrame with the schema ' ' customer_id LONG, predictions DOUBLE ' ' ?
Which configuration parameter directly affects the size of a spark-partition upon ingestion of data into Spark?
A data engineer is performing a join operating to combine values from a static userlookup table with a streaming DataFrame streamingDF.
Which code block attempts to perform an invalid stream-static join?
A table in the Lakehouse named customer_churn_params is used in churn prediction by the machine learning team. The table contains information about customers derived from a number of upstream sources. Currently, the data engineering team populates this table nightly by overwriting the table with the current valid values derived from upstream data sources.
The churn prediction model used by the ML team is fairly stable in production. The team is only interested in making predictions on records that have changed in the past 24 hours.
Which approach would simplify the identification of these changed records?
A healthcare analytics team is implementing a dimensional model in Delta Lake for patient care analysis. They have a date dimension table and are evaluating design options to ensure it supports a wide range of time-based analyses.
Which design approach for the date dimension will support efficient time-based querying and aggregation?
While reviewing a query ' s execution in the Databricks Query Profiler, a data engineer observes that the Top Operators panel shows a Sort operator with high Time Spent and Memory Peak metrics. The Spark UI also reports frequent data spilling .
How should the data engineer address this issue?
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df. The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Events are recorded once per minute per device.
df has the following schema: device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT
Code block:
df.withWatermark( " event_time " , " 10 minutes " )
.groupBy(
________,
" device_id "
)
.agg(
avg( " temp " ).alias( " avg_temp " ),
avg( " humidity " ).alias( " avg_humidity " )
)
.writeStream
.format( " delta " )
.saveAsTable( " sensor_avg " )
Which line of code correctly fills in the blank within the code block to complete this task?
PDF + Testing Engine

Testing Engine
PDF (Q&A)

