Databricks-Machine-Learning-Professional Databricks Certified Machine Learning Professional Questions and Answers
A machine learning engineer wants to log and deploy a model as an MLflow pyfunc model. They have custom preprocessing that needs to be completed on feature variables prior to fitting the model or computing predictions using that model. They decide to wrap this preprocessing in a custom model class ModelWithPreprocess, where the preprocessing is performed when calling fit and when calling predict. They then log the fitted model of the ModelWithPreprocess class as a pyfunc model.
Which of the following is a benefit of this approach when loading the logged pyfunc model for downstream deployment?
A data scientist is utilizing MLflow to track their machine learning experiments. After completing a series of runs for the experiment with experiment ID exp_id, the data scientist wants to programmatically work with the experiment run data in a Spark DataFrame. They have an active MLflow Client client and an active Spark session spark.
Which of the following lines of code can be used to obtain run-level results for exp_id in a Spark DataFrame?
Which of the following is a reason for using Jensen-Shannon (JS) distance over a Kolmogorov-Smirnov (KS) test for numeric feature drift detection?
A data scientist is using MLflow to track their machine learning experiment. As a part of each MLflow run, they are performing hyperparameter tuning. The data scientist would like to have one parent run for the tuning process with a child run for each unique combination of hyperparameter values.
They are using the following code block:
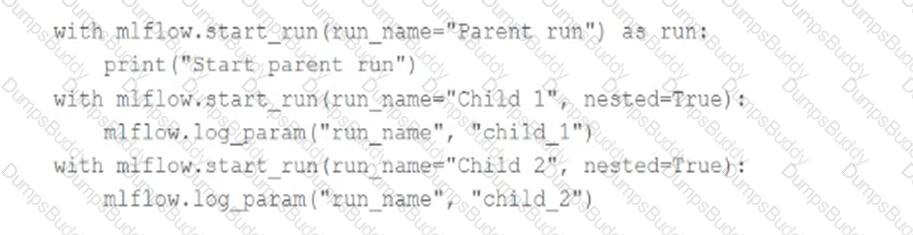
The code block is not nesting the runs in MLflow as they expected.
Which of the following changes does the data scientist need to make to the above code block so that it successfully nests the child runs under the parent run in MLflow?
A data scientist has developed a scikit-learn modelsklearn_modeland they want to log the model using MLflow.
They write the following incomplete code block:

Which of the following lines of code can be used to fill in the blank so the code block can successfully complete the task?
Which of the following machine learning model deployment paradigms is the most common for machine learning projects?
A machine learning engineer is in the process of implementing a concept drift monitoring solution. They are planning to use the following steps:
1. Deploy a model to production and compute predicted values
2. Obtain the observed (actual) label values
3. _____
4. Run a statistical test to determine if there are changes over time
Which of the following should be completed as Step #3?
A machine learning engineer needs to deliver predictions of a machine learning model in real-time. However, the feature values needed for computing the predictions are available one week before the query time.
Which of the following is a benefit of using a batch serving deployment in this scenario rather than a real-time serving deployment where predictions are computed at query time?
A machine learning engineer wants to log feature importance data from a CSV file at path importance_path with an MLflow run for model model.
Which of the following code blocks will accomplish this task inside of an existing MLflow run block?
Options:


mlflow.log_data(importance_path, "feature-importance.csv")
mlflow.log_artifact(importance_path, "feature-importance.csv")
None of these code blocks tan accomplish the task.
A machine learning engineer wants to programmatically create a new Databricks Job whose schedule depends on the result of some automated tests in a machine learning pipeline.
Which of the following Databricks tools can be used to programmatically create the Job?
A machine learning engineer has developed a model and registered it using the FeatureStoreClient fs. The model has model URI model_uri. The engineer now needs to perform batch inference on customer-level Spark DataFrame spark_df, but it is missing a few of the static features that were used when training the model. The customer_id column is the primary key of spark_df and the training set used when training and logging the model.
Which of the following code blocks can be used to compute predictions for spark_df when the missing feature values can be found in the Feature Store by searching for features by customer_id?
A machine learning engineer is using the following code block as part of a batch deployment pipeline:

Which of the following changes needs to be made so this code block will work when theinferencetable is a stream source?
Which of the following is a simple statistic to monitor for categorical feature drift?
PDF + Testing Engine

Testing Engine
PDF (Q&A)

