Databricks-Machine-Learning-Associate Databricks Certified Machine Learning Associate Exam Questions and Answers
A data scientist is using MLflow to track their machine learning experiment. As a part of each of their MLflow runs, they are performing hyperparameter tuning. The data scientist would like to have one parent run for the tuning process with a child run for each unique combination of hyperparameter values. All parent and child runs are being manually started with mlflow.start_run.
Which of the following approaches can the data scientist use to accomplish this MLflow run organization?
A data scientist wants to parallelize the training of trees in a gradient boosted tree to speed up the training process. A colleague suggests that parallelizing a boosted tree algorithm can be difficult.
Which of the following describes why?
A data scientist is wanting to explore summary statistics for Spark DataFrame spark_df. The data scientist wants to see the count, mean, standard deviation, minimum, maximum, and interquartile range (IQR) for each numerical feature.
Which of the following lines of code can the data scientist run to accomplish the task?
A data scientist has created two linear regression models. The first model uses price as a label variable and the second model uses log(price) as a label variable. When evaluating the RMSE of each model bycomparing the label predictions to the actual price values, the data scientist notices that the RMSE for the second model is much larger than the RMSE of the first model.
Which of the following possible explanations for this difference is invalid?
What is the name of the method that transforms categorical features into a series of binary indicator feature variables?
Which of the following tools can be used to distribute large-scale feature engineering without the use of a UDF or pandas Function API for machine learning pipelines?
A team is developing guidelines on when to use various evaluation metrics for classification problems. The team needs to provide input on when to use the F1 score over accuracy.
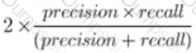
Which of the following suggestions should the team include in their guidelines?
A machine learning engineer has grown tired of needing to install the MLflow Python library on each of their clusters. They ask a senior machine learning engineer how their notebooks can load the MLflow library without installing it each time. The senior machine learning engineer suggests that they use Databricks Runtime for Machine Learning.
Which of the following approaches describes how the machine learning engineer can begin using Databricks Runtime for Machine Learning?
A data scientist wants to tune a set of hyperparameters for a machine learning model. They have wrapped a Spark ML model in the objective functionobjective_functionand they have defined the search spacesearch_space.
As a result, they have the following code block:

Which of the following changes do they need to make to the above code block in order to accomplish the task?
A data scientist wants to use Spark ML to one-hot encode the categorical features in their PySpark DataFramefeatures_df. A list of the names of the string columns is assigned to theinput_columnsvariable.
They have developed this code block to accomplish this task:
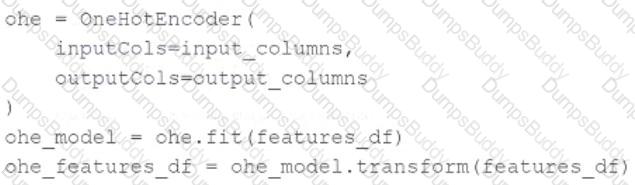
The code block is returning an error.
Which of the following adjustments does the data scientist need to make to accomplish this task?
A data scientist wants to efficiently tune the hyperparameters of a scikit-learn model. They elect to use the Hyperopt library'sfminoperation to facilitate this process. Unfortunately, the final model is not very accurate. The data scientist suspects that there is an issue with theobjective_functionbeing passed as an argument tofmin.
They use the following code block to create theobjective_function:

Which of the following changes does the data scientist need to make to theirobjective_functionin order to produce a more accurate model?
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
A data scientist has a Spark DataFrame spark_df. They want to create a new Spark DataFrame that contains only the rows from spark_df where the value in column price is greater than 0.
Which of the following code blocks will accomplish this task?
A data scientist wants to efficiently tune the hyperparameters of a scikit-learn model in parallel. They elect to use the Hyperopt library to facilitate this process.
Which of the following Hyperopt tools provides the ability to optimize hyperparameters in parallel?
Which of the following describes the relationship between native Spark DataFrames and pandas API on Spark DataFrames?
A machine learning engineer wants to parallelize the training of group-specific models using the Pandas Function API. They have developed thetrain_modelfunction, and they want to apply it to each group of DataFramedf.
They have written the following incomplete code block:

Which of the following pieces of code can be used to fill in the above blank to complete the task?
A data scientist has created a linear regression model that useslog(price)as a label variable. Using this model, they have performed inference and the predictions and actual label values are in Spark DataFramepreds_df.
They are using the following code block to evaluate the model:
regression_evaluator.setMetricName("rmse").evaluate(preds_df)
Which of the following changes should the data scientist make to evaluate the RMSE in a way that is comparable withprice?
A health organization is developing a classification model to determine whether or not a patient currently has a specific type of infection. The organization's leaders want to maximize the number of positive cases identified by the model.
Which of the following classification metrics should be used to evaluate the model?
PDF + Testing Engine

Testing Engine
PDF (Q&A)

