Databricks-Certified-Data-Engineer-Associate Databricks Certified Data Engineer Associate Exam Questions and Answers
Which of the following commands will return the location of database customer360?
A data engineer has been provided a PySpark DataFrame named df with columns product and revenue. The data engineer needs to compute complex aggregations to determine each product ' s total revenue, average revenue, and transaction count.
Which code snippet should the data engineer use?
A)
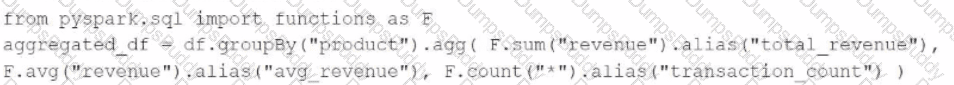
B)

C)

D)

A data engineer is configuring Unity Catalog in Databricks and needs to assign a role to a user who should have the ability to grant and revoke privileges on various data objects within a specific schema but should not have read/write access over the schema or its objects.
Which role should the data engineer assign to this user?
A data engineer needs Task C to run only when Task A succeeds and Task B fails.
Which dependency configuration implements this conditional logic?
A Data Engineer is building a simple data pipeline using Delta Live Tables (DLT) in Databricksto ingest customer data. The raw customer data is stored in a cloud storage location in JSON format. The task is to create a DLT pipeline that reads the rawJSON data and writes it into a Delta table for further processing.
Which code snippet will correctly ingest the raw JSON data and create a Delta table using DLT?
A)

B)

C)

D)

A data engineer is onboarding a new Bronze ingestion pipeline in Databricks with Unity Catalog. The team wants Databricks to handle storage layout, apply platform optimizations over time, and simplify lifecycle management so that when a table is dropped, its underlying data is also cleaned up according to Databricks-managed retention policies.
Which table type should the data engineer create for these ingestion tables?
A data engineer needs to determine whether to use the built-in Databricks Notebooks versioning or version their project using Databricks Repos.
Which of the following is an advantage of using Databricks Repos over the Databricks Notebooks versioning?
Which single Databricks CLI command deploys local bundle assets to the target workspace specified in the bundle configuration file?
A data engineer is maintaining an ETL pipeline code with a GitHub repository linked to their Databricks account. The data engineer wants to deploy the ETL pipeline to production as a databricks workflow.
Which approach should the data engineer use?
A Databricks Job with four sequential tasks is executed. The job fails at Task 3. After the root cause is fixed, the data engineer needs to complete the workflow without rerunning the successful Tasks 1 and 2.
Which action on the Job Run details page allows the engineer to resume execution from the point of failure?
A new data engineering team has been assigned to work on a project. The team will need access to database customers in order to see what tables already exist. The team has its own group team.
Which of the following commands can be used to grant the necessary permission on the entire database to the new team?
A data engineer is troubleshooting two different pipeline failures:
Pipeline A fails with a java.lang.OutOfMemoryError immediately after display(df.collect()) is called on a 100 GB dataset.
Pipeline B fails during a wide transformation joining two large tables, with an ExecutorLostFailure message indicating executor-memory exhaustion during the shuffle.
Which action should the data engineer take to address these two issues?
A data engineer needs to ingest from both streaming and batch sources for a firm that relies on highly accurate data. Occasionally, some of the data picked up by the sensors that provide a streaming input are outside the expected parameters. If this occurs, the data must be dropped, but the stream should not fail.
Which feature of Delta Live Tables meets this requirement?
A data analyst has created a Delta table sales that is used by the entire data analysis team. They want help from the data engineering team to implement a series of tests to ensure the data is clean. However, the data engineering team uses Python for its tests rather than SQL.
Which of the following commands could the data engineering team use to access sales in PySpark?
A data engineer uses the Databricks workspace UI with Unity Catalog enabled. In Catalog Explorer, they select catalog corp_marketing, then schema campaigns, and see table email_stats. The engineer must let the growth-analysts group read email_stats from its SQL warehouses, but not create, alter, or delete any objects in corp_marketing or campaigns.
Which action sequence meets the requirement?
A data engineer is attempting to grant a user access to a view. They successfully run the following command:
GRANT SELECT ON VIEW sales_catalog.market_data.summary
TO analyst_group;
However, the analyst still receives an “Insufficient Permissions” error when trying to query the view.
In which order should the engineer verify the hierarchy of securable objects to ensure that the analyst has the necessary usage permissions?
A data engineer needs to conduct Exploratory Analysis on data residing in a database that is within the company ' s custom-defined network in the cloud. The data engineer is using SQL for this task.
Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
A data engineering project involves processing large batches of data on a daily schedule using ETL. The jobs are resource-intensive and vary in size, requiring a scalable, cost-efficient compute solution that can automatically scale based on the workload.
Which compute approach will satisfy the needs described?
A data engineer has been given a new record of data:
id STRING = ' a1 '
rank INTEGER = 6
rating FLOAT = 9.4
Which of the following SQL commands can be used to append the new record to an existing Delta table my_table?
Which of the following is a benefit of the Databricks Lakehouse Platform embracing open source technologies?
A data engineer is cleaning a Bronze table. The requirement is to eliminate rows where either the customer_email field or the customer_phone field is NULL. The cleaning must be performed in one operation using a single method call.
Which PySpark approach supports filtering multiple columns for NULL values in one call?
A data engineer needs to apply custom logic to identify employees with more than 5 years of experience in array column employees in table stores. The custom logic should create a new column exp_employees that is an array of all of the employees with more than 5 years of experience for each row. In order to apply this custom logic at scale, the data engineer wants to use the FILTER higher-order function.
Which of the following code blocks successfully completes this task?

Which two components function in the DB platform architecture’s control plane? (Choose two.)
A new data engineering team team has been assigned to an ELT project. The new data engineering team will need full privileges on the table sales to fully manage the project.
Which of the following commands can be used to grant full permissions on the database to the new data engineering team?
A data engineer has finished developing a new Declarative Automation Bundle, formerly known as a Databricks Asset Bundle, for a streaming pipeline. The engineer must verify that the configuration is syntactically correct, deploy the code to the workspace, and finally trigger the pipeline to confirm that it runs as expected.
Which sequence of Databricks CLI commands performs these steps in the correct order?
A data engineer is designing a cost-optimized, event-driven pipeline. They configure a Lakeflow Job with a File Arrival trigger to watch an Amazon S3 bucket. The job runs a notebook that uses Auto Loader with trigger(availableNow=True) to ingest data into a Bronze table.
What is the technical relationship between the File Arrival trigger and Auto Loader in this integration pattern?
A data engineer is attempting to write Python and SQL in the same command cell and is running into an error The engineer thought that it was possible to use a Python variable in a select statement.
Why does the command fail?
A data engineer is cleaning a Bronze table that receives the same customer records from multiple source systems. Duplicate rows have the same customer_id and email values but different ingestion_timestamp values. The Silver table should contain only one record for each unique combination of customer_id and email.
Which PySpark operation correctly deduplicates the records based on the business keys?
A data engineer is getting a partner organization up to speed with Databricks account. Both teams share some business use cases. The data engineer has to share some of your Unity-Catalog managed delta tables and the notebook jobs creating those tables with the partner organization.
How can the data engineer seamlessly share the required information?
A data engineer wants to create a new table containing the names of customers who live in France.
They have written the following command:
CREATE TABLE customersInFrance
_____ AS
SELECT id,
firstName,
lastName
FROM customerLocations
WHERE country = ’FRANCE’;
A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (Pll).
Which line of code fills in the above blank to successfully complete the task?
A data engineer needs access to a table new_table, but they do not have the correct permissions. They can ask the table owner for permission, but they do not know who the table owner is.
Which of the following approaches can be used to identify the owner of new_table?
A data engineer needs to combine sales data from an on-premises PostgreSQL database with customer data in Azure Synapse for a comprehensive report. The goal is to avoid data duplication and ensure up-to-date information
How should the data engineer achieve this using Databricks?
A data engineer at a company that uses Databricks with Unity Catalog needs to share a collection of tables with an external partner who also uses a Databricks workspace enabled for Unity Catalog. The data engineer decides to use Delta Sharing to accomplish this.
What is the first piece of information the data engineer should request from the external partner to set up Delta Sharing?
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Development mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
A data engineer has realized that the data files associated with a Delta table are incredibly small. They want to compact the small files to form larger files to improve performance.
Which of the following keywords can be used to compact the small files?
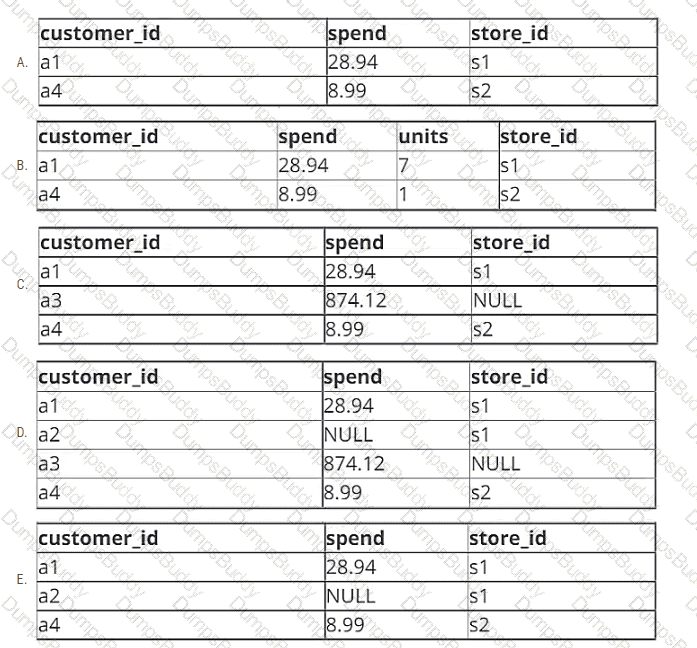
A data engineer is working with two tables. Each of these tables is displayed below in its entirety.

The data engineer runs the following query to join these tables together:

Which of the following will be returned by the above query?
A data engineer wants to create a data entity from a couple of tables. The data entity must be used by other data engineers in other sessions. It also must be saved to a physical location.
Which of the following data entities should the data engineer create?
A Python file is ready to go into production and the client wants to use the cheapest but most efficient type of cluster possible. The workload is quite small, only processing 10GBs of data with only simple joins and no complex aggregations or wide transformations.
Which cluster meets the requirement?
A data engineer has developed a data pipeline to ingest data from a JSON source using Auto Loader, but the engineer has not provided any type inference or schema hints in their pipeline. Upon reviewing the data, the data engineer has noticed that all of the columns in the target table are of the string type despite some of the fields only including float or boolean values.
Which of the following describes why Auto Loader inferred all of the columns to be of the string type?
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which change will need to be made to the pipeline when migrating to Delta Live Tables?
A data engineer works for an organization that must meet a stringent Service Level Agreement (SLA) that demands minimal runtime errors and high availability for its data processing pipelines. The data engineer wants to avoid the operational overhead of managing and tuning clusters.
Which architectural solution will meet the requirements?
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > ' 2020-01-01 ' ) ON VIOLATION DROP ROW
What is the expected behavior when a batch of data containing data that violates these constraints is processed?
A data engineering team ingests customer transaction data from three enterprise sources: a SQL database, Amazon S3, and an Apache Kafka stream. The data must maintain lineage and support compliance audits that require access to historical snapshots.
Which Lakeflow Connect configuration satisfies both the governance and audit requirements?
Which of the following describes a scenario in which a data team will want to utilize cluster pools?
The Delta transaction log for the ‘students’ tables is shown using the ‘DESCRIBE HISTORY students’ command. A Data Engineer needs to query the table as it existed before the UPDATE operation listed in the log.
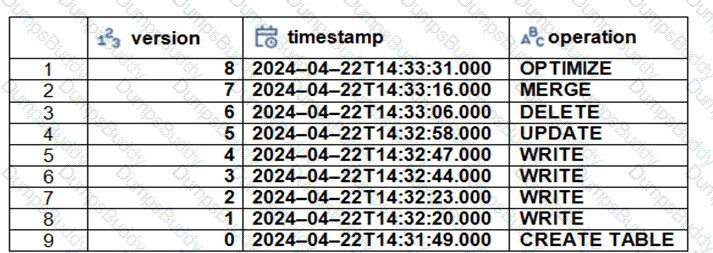
Which command should the Data Engineer use to achieve this? (Choose two.)
A data engineer is attempting to drop a Spark SQL table my_table. The data engineer wants to delete all table metadata and data.
They run the following command:
DROP TABLE IF EXISTS my_table
While the object no longer appears when they run SHOW TABLES, the data files still exist.
Which of the following describes why the data files still exist and the metadata files were deleted?
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.

The code block used by the data engineer is below:
Which line of code should the data engineer use to fill in the blank if the data engineer only wants the query to execute a micro-batch to process data every 5 seconds?
An organization plans to share a large dataset stored in a Databricks workspace on AWS with a partner organization whose Databricks workspace is hosted on Azure. The data engineer wants to minimize data transfer costs while ensuring secure and efficient data sharing.
Which strategy will reduce data egress costs associated with cross-cloud data sharing?
A governance team is evaluating whether to use Unity Catalog attribute-based access control policies or manually applied row filters and column masks to protect sensitive data across its catalog.
Why should the team use attribute-based access control policies instead of manually applied row filters and column masks?
A data engineer has joined an existing project and they see the following query in the project repository:
CREATE STREAMING LIVE TABLE loyal_customers AS
SELECT customer_id -
FROM STREAM(LIVE.customers)
WHERE loyalty_level = ' high ' ;
Which of the following describes why the STREAM function is included in the query?
A data engineer runs a statement every day to copy the previous day’s sales into the table transactions. Each day’s sales are in their own file in the location " /transactions/raw " .
Today, the data engineer runs the following command to complete this task:

After running the command today, the data engineer notices that the number of records in table transactions has not changed.
Which of the following describes why the statement might not have copied any new records into the table?
A departing platform owner currently holds ownership of multiple catalogs and controls storage credentials and external locations. The data engineer wants to ensure continuity: transfer catalog ownership to the platform team group, delegate ongoing privilege management, and retain the ability to receive and share data via Delta Sharing .
Which role must be in place to perform these actions across the metastore?
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.
The code block used by the data engineer is below:

If the data engineer only wants the query to process all of the available data in as many batches as required, which of the following lines of code should the data engineer use to fill in the blank?
A data engineer has a Job with multiple tasks that runs nightly. Each of the tasks runs slowly because the clusters take a long time to start.
Which of the following actions can the data engineer perform to improve the start up time for the clusters used for the Job?
A data engineer wants to reduce costs and optimize cloud spending. The data engineer has decided to use Databricks Serverless for lowering cloud costs while maintaining existing SLAs.
What is the first step in migrating to Databricks Serverless?
A data engineering team has two tables. The first table march_transactions is a collection of all retail transactions in the month of March. The second table april_transactions is a collection of all retail transactions in the month of April. There are no duplicate records between the tables.
Which of the following commands should be run to create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records?
A data engineer is reviewing the documentation on audit logs in Databricks for compliance purposes and needs to understand the format in which audit logs output events.
How are events formatted in Databricks audit logs?
A data analyst has a series of queries in a SQL program. The data analyst wants this program to run every day. They only want the final query in the program to run on Sundays. They ask for help from the data engineering team to complete this task.
Which of the following approaches could be used by the data engineering team to complete this task?
A data engineer is transforming a Bronze table containing API-response data into a Silver table. The Bronze table has a user_profile column of type STRING that contains JSON data. An example value is:
{ " user_id " : " 12345 " , " name " : " John Smith " , " age " :32, " email " : " john@example.com " }
The Silver table must make this data easily queryable for analytics without requiring JSON parsing in every downstream query.
Which approach standardizes this column for the Silver table?
A data engineer has realized that they made a mistake when making a daily update to a table. They need to use Delta time travel to restore the table to a version that is 3 days old. However, when the data engineer attempts to time travel to the older version, they are unable to restore the data because the data files have been deleted.
Which of the following explains why the data files are no longer present?
A data engineer is building a nightly batch ETL pipeline that processes very large volumes of raw JSON logs from a data lake into Delta tables for reporting. The data arrives in bulk once per day, and the pipeline takes several hours to complete. Cost efficiency is important , but performance and reliable completion of the pipeline are the highest priorities.
Which type of Databricks cluster should the data engineer configure?
PDF + Testing Engine

Testing Engine
PDF (Q&A)

