Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 Databricks Certified Associate Developer for Apache Spark 3.5 – Python Questions and Answers
A Spark engineer must select an appropriate deployment mode for the Spark jobs.
What is the benefit of using cluster mode in Apache Spark™?
Given the code fragment:
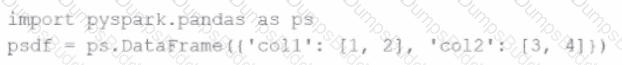
import pyspark.pandas as ps
psdf = ps.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
Which method is used to convert a Pandas API on Spark DataFrame (pyspark.pandas.DataFrame) into a standard PySpark DataFrame (pyspark.sql.DataFrame)?
An MLOps engineer is building a Pandas UDF that applies a language model that translates English strings into Spanish. The initial code is loading the model on every call to the UDF, which is hurting the performance of the data pipeline.
The initial code is:

def in_spanish_inner(df: pd.Series) -> pd.Series:
model = get_translation_model(target_lang='es')
return df.apply(model)
in_spanish = sf.pandas_udf(in_spanish_inner, StringType())
How can the MLOps engineer change this code to reduce how many times the language model is loaded?
37 of 55.
A data scientist is working with a Spark DataFrame called customerDF that contains customer information.
The DataFrame has a column named email with customer email addresses.
The data scientist needs to split this column into username and domain parts.
Which code snippet splits the email column into username and domain columns?
How can a Spark developer ensure optimal resource utilization when running Spark jobs in Local Mode for testing?
Options:
Given this view definition:
df.createOrReplaceTempView("users_vw")
Which approach can be used to query the users_vw view after the session is terminated?
Options:
A data engineer needs to persist a file-based data source to a specific location. However, by default, Spark writes to the warehouse directory (e.g., /user/hive/warehouse). To override this, the engineer must explicitly define the file path.
Which line of code ensures the data is saved to a specific location?
Options:
33 of 55.
The data engineering team created a pipeline that extracts data from a transaction system.
The transaction system stores timestamps in UTC, and the data engineers must now transform the transaction_datetime field to the “America/New_York” timezone for reporting.
Which code should be used to convert the timestamp to the target timezone?
A data analyst builds a Spark application to analyze finance data and performs the following operations: filter, select, groupBy, and coalesce.
Which operation results in a shuffle?
A Data Analyst needs to retrieve employees with 5 or more years of tenure.
Which code snippet filters and shows the list?
38 of 55.
A data engineer is working with Spark SQL and has a large JSON file stored at /data/input.json.
The file contains records with varying schemas, and the engineer wants to create an external table in Spark SQL that:
Reads directly from /data/input.json.
Infers the schema automatically.
Merges differing schemas.
Which code snippet should the engineer use?
8 of 55.
A data scientist at a large e-commerce company needs to process and analyze 2 TB of daily customer transaction data. The company wants to implement real-time fraud detection and personalized product recommendations.
Currently, the company uses a traditional relational database system, which struggles with the increasing data volume and velocity.
Which feature of Apache Spark effectively addresses this challenge?
15 of 55.
A data engineer is working on a Streaming DataFrame (streaming_df) with the following streaming data:
id
name
count
timestamp
1
Delhi
20
2024-09-19T10:11
1
Delhi
50
2024-09-19T10:12
2
London
50
2024-09-19T10:15
3
Paris
30
2024-09-19T10:18
3
Paris
20
2024-09-19T10:20
4
Washington
10
2024-09-19T10:22
Which operation is supported with streaming_df?
A data engineer is working with a large JSON dataset containing order information. The dataset is stored in a distributed file system and needs to be loaded into a Spark DataFrame for analysis. The data engineer wants to ensure that the schema is correctly defined and that the data is read efficiently.
Which approach should the data scientist use to efficiently load the JSON data into a Spark DataFrame with a predefined schema?
36 of 55.
What is the main advantage of partitioning the data when persisting tables?
A data scientist is working on a large dataset in Apache Spark using PySpark. The data scientist has a DataFrame df with columns user_id, product_id, and purchase_amount and needs to perform some operations on this data efficiently.
Which sequence of operations results in transformations that require a shuffle followed by transformations that do not?
A data engineer wants to create a Streaming DataFrame that reads from a Kafka topic called feed.

Which code fragment should be inserted in line 5 to meet the requirement?
Code context:
spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.[LINE 5] \
.load()
Options:
2 of 55. Which command overwrites an existing JSON file when writing a DataFrame?
A data engineer is working on the DataFrame:
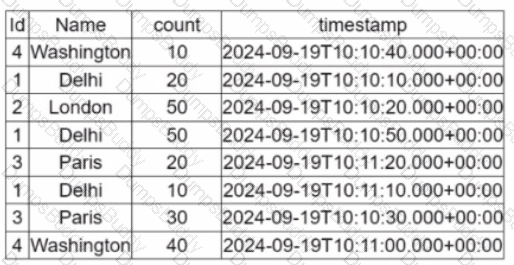
(Referring to the table image: it has columns Id, Name, count, and timestamp.)
Which code fragment should the engineer use to extract the unique values in the Name column into an alphabetically ordered list?
A Spark application is experiencing performance issues in client mode because the driver is resource-constrained.
How should this issue be resolved?
A Spark application developer wants to identify which operations cause shuffling, leading to a new stage in the Spark execution plan.
Which operation results in a shuffle and a new stage?
Given the code:

df = spark.read.csv("large_dataset.csv")
filtered_df = df.filter(col("error_column").contains("error"))
mapped_df = filtered_df.select(split(col("timestamp"), " ").getItem(0).alias("date"), lit(1).alias("count"))
reduced_df = mapped_df.groupBy("date").sum("count")
reduced_df.count()
reduced_df.show()
At which point will Spark actually begin processing the data?
A Spark developer is building an app to monitor task performance. They need to track the maximum task processing time per worker node and consolidate it on the driver for analysis.
Which technique should be used?
A data engineer needs to write a Streaming DataFrame as Parquet files.
Given the code:

Which code fragment should be inserted to meet the requirement?
A)

B)

C)

D)
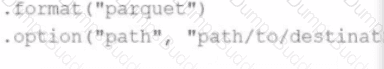
Which code fragment should be inserted to meet the requirement?
34 of 55.
A data engineer is investigating a Spark cluster that is experiencing underutilization during scheduled batch jobs.
After checking the Spark logs, they noticed that tasks are often getting killed due to timeout errors, and there are several warnings about insufficient resources in the logs.
Which action should the engineer take to resolve the underutilization issue?
47 of 55.
A data engineer has written the following code to join two DataFrames df1 and df2:
df1 = spark.read.csv("sales_data.csv")
df2 = spark.read.csv("product_data.csv")
df_joined = df1.join(df2, df1.product_id == df2.product_id)
The DataFrame df1 contains ~10 GB of sales data, and df2 contains ~8 MB of product data.
Which join strategy will Spark use?
A Spark DataFrame df is cached using the MEMORY_AND_DISK storage level, but the DataFrame is too large to fit entirely in memory.
What is the likely behavior when Spark runs out of memory to store the DataFrame?
25 of 55.
A Data Analyst is working on employees_df and needs to add a new column where a 10% tax is calculated on the salary.
Additionally, the DataFrame contains the column age, which is not needed.
Which code fragment adds the tax column and removes the age column?
An engineer notices a significant increase in the job execution time during the execution of a Spark job. After some investigation, the engineer decides to check the logs produced by the Executors.
How should the engineer retrieve the Executor logs to diagnose performance issues in the Spark application?
32 of 55.
A developer is creating a Spark application that performs multiple DataFrame transformations and actions. The developer wants to maintain optimal performance by properly managing the SparkSession.
How should the developer handle the SparkSession throughout the application?
42 of 55.
A developer needs to write the output of a complex chain of Spark transformations to a Parquet table called events.liveLatest.
Consumers of this table query it frequently with filters on both year and month of the event_ts column (a timestamp).
The current code:
from pyspark.sql import functions as F
final = df.withColumn("event_year", F.year("event_ts")) \
.withColumn("event_month", F.month("event_ts")) \
.bucketBy(42, ["event_year", "event_month"]) \
.saveAsTable("events.liveLatest")
However, consumers report poor query performance.
Which change will enable efficient querying by year and month?
A data engineer is working on a real-time analytics pipeline using Apache Spark Structured Streaming. The engineer wants to process incoming data and ensure that triggers control when the query is executed. The system needs to process data in micro-batches with a fixed interval of 5 seconds.
Which code snippet the data engineer could use to fulfil this requirement?
A)

B)

C)

D)

Options:
A data scientist has identified that some records in the user profile table contain null values in any of the fields, and such records should be removed from the dataset before processing. The schema includes fields like user_id, username, date_of_birth, created_ts, etc.
The schema of the user profile table looks like this:
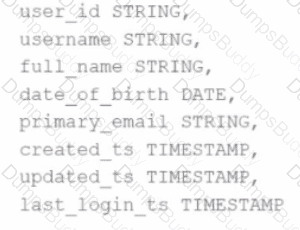
Which block of Spark code can be used to achieve this requirement?
Options:
A data engineer uses a broadcast variable to share a DataFrame containing millions of rows across executors for lookup purposes. What will be the outcome?
A data engineer is working on a Streaming DataFrame streaming_df with the given streaming data:
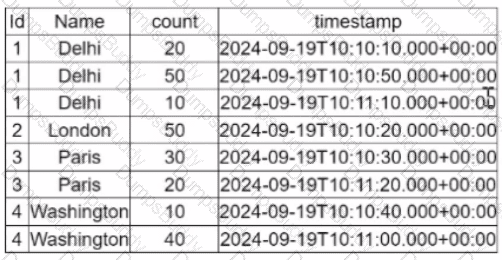
Which operation is supported with streamingdf ?
PDF + Testing Engine

Testing Engine
PDF (Q&A)

