AIP-210 CertNexus Certified Artificial Intelligence Practitioner (CAIP) Questions and Answers
Which two encodes can be used to transform categories data into numerical features? (Select two.)
In a self-driving car company, ML engineers want to develop a model for dynamic pathing. Which of following approaches would be optimal for this task?
Which of the following describes a neural network without an activation function?
You and your team need to process large datasets of images as fast as possible for a machine learning task. The project will also use a modular framework with extensible code and an active developer community. Which of the following would BEST meet your needs?
Which two of the following statements about the beta value in an A/B test are accurate? (Select two.)
When working with textual data and trying to classify text into different languages, which approach to representing features makes the most sense?
A data scientist is tasked to extract business intelligence from primary data captured from the public. Which of the following is the most important aspect that the scientist cannot forget to include?
Which of the following is the correct definition of the quality criteria that describes completeness?
Which of the following can benefit from deploying a deep learning model as an embedded model on edge devices?
Which type of regression represents the following formula: y = c + b*x, where y = estimated dependent variable score, c = constant, b = regression coefficient, and x = score on the independent variable?
Which of the following can take a question in natural language and return a precise answer to the question?
Which of the following unsupervised learning models can a bank use for fraud detection?
A classifier has been implemented to predict whether or not someone has a specific type of disease. Considering that only 1% of the population in the dataset has this disease, which measures will work the BEST to evaluate this model?
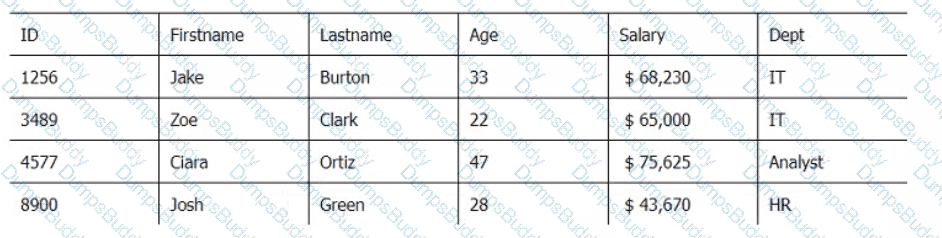
Below are three tables: Employees, Departments, and Directors.
Employee_Table
Department_Table
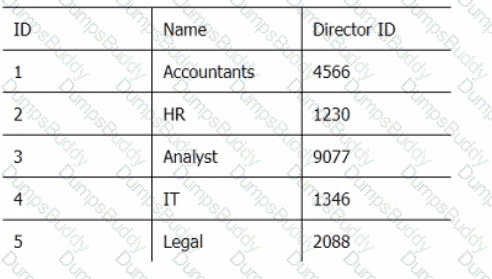
Director_Table
ID
Firstname
Lastname
Age
Salary
DeptJD
4566
Joey
Morin
62
$ 122,000
1
1230
Sam
Clarck
43
$ 95,670
2
9077
Lola
Russell
54
$ 165,700
3
1346
Lily
Cotton
46
$ 156,000
4
2088
Beckett
Good
52
$ 165,000
5
Which SQL query provides the Directors' Firstname, Lastname, the name of their departments, and the average employee's salary?
A product manager is designing an Artificial Intelligence (AI) solution and wants to do so responsibly, evaluating both positive and negative outcomes.
The team creates a shared taxonomy of potential negative impacts and conducts an assessment along vectors such as severity, impact, frequency, and likelihood.
Which modeling technique does this team use?
Your dependent variable data is a proportion. The observed range of your data is 0.01 to 0.99. The instrument used to generate the dependent variable data is known to generate low quality data for values close to 0 and close to 1. A colleague suggests performing a logit-transformation on the data prior to performing a linear regression. Which of the following is a concern with this approach?
Definition of logit-transformation
If p is the proportion: logit(p)=log(p/(l-p))
PDF + Testing Engine

Testing Engine
PDF (Q&A)

