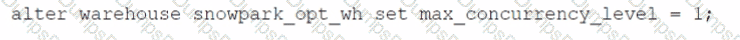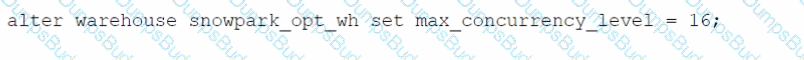ARA-C01 SnowPro Advanced: Architect Certification Exam Questions and Answers
Which statements describe characteristics of the use of materialized views in Snowflake? (Choose two.)
A Snowflake Architect created a new data share and would like to verify that only specific records in secure views are visible within the data share by the consumers.
What is the recommended way to validate data accessibility by the consumers?
An Architect with the ORGADMIN role wants to change a Snowflake account from an Enterprise edition to a Business Critical edition.
How should this be accomplished?
What is a key consideration when setting up search optimization service for a table?
In a managed access schema, what are characteristics of the roles that can manage object privileges? (Select TWO).
A global company with operations in North America, Europe, and Asia needs to secure its Snowflake environment with a focus on data privacy, secure connectivity, and access control. The company uses AWS and must ensure secure data transfers that comply with regional regulations.
How can these requirements be met? (Select TWO).
Which command will create a schema without Fail-safe and will restrict object owners from passing on access to other users?
A company has a Snowflake environment running in AWS us-west-2 (Oregon). The company needs to share data privately with a customer who is running their Snowflake environment in Azure East US 2 (Virginia).
What is the recommended sequence of operations that must be followed to meet this requirement?
The following DDL command was used to create a task based on a stream:

Assuming MY_WH is set to auto_suspend – 60 and used exclusively for this task, which statement is true?
An Architect is designing a solution that will be used to process changed records in an orders table. Newly-inserted orders must be loaded into the f_orders fact table, which will aggregate all the orders by multiple dimensions (time, region, channel, etc.). Existing orders can be updated by the sales department within 30 days after the order creation. In case of an order update, the solution must perform two actions:
1. Update the order in the f_0RDERS fact table.
2. Load the changed order data into the special table ORDER _REPAIRS.
This table is used by the Accounting department once a month. If the order has been changed, the Accounting team needs to know the latest details and perform the necessary actions based on the data in the order_repairs table.
What data processing logic design will be the MOST performant?
What Snowflake system functions are used to view and or monitor the clustering metadata for a table? (Select TWO).
What considerations need to be taken when using database cloning as a tool for data lifecycle management in a development environment? (Select TWO).
A company is designing its serving layer for data that is in cloud storage. Multiple terabytes of the data will be used for reporting. Some data does not have a clear use case but could be useful for experimental analysis. This experimentation data changes frequently and is sometimes wiped out and replaced completely in a few days.
The company wants to centralize access control, provide a single point of connection for the end-users, and maintain data governance.
What solution meets these requirements while MINIMIZING costs, administrative effort, and development overhead?
An Architect is designing Snowflake architecture to support fast Data Analyst reporting. To optimize costs, the virtual warehouse is configured to auto-suspend after 2 minutes of idle time. Queries are run once in the morning after refresh, but later queries run slowly.
Why is this occurring?
When loading data into a table that captures the load time in a column with a default value of either CURRENT_TIME () or CURRENT_TIMESTAMP() what will occur?
Two queries are run on the customer_address table:
create or replace TABLE CUSTOMER_ADDRESS ( CA_ADDRESS_SK NUMBER(38,0), CA_ADDRESS_ID VARCHAR(16), CA_STREET_NUMBER VARCHAR(IO) CA_STREET_NAME VARCHAR(60), CA_STREET_TYPE VARCHAR(15), CA_SUITE_NUMBER VARCHAR(10), CA_CITY VARCHAR(60), CA_COUNTY
VARCHAR(30), CA_STATE VARCHAR(2), CA_ZIP VARCHAR(10), CA_COUNTRY VARCHAR(20), CA_GMT_OFFSET NUMBER(5,2), CA_LOCATION_TYPE
VARCHAR(20) );
ALTER TABLE DEMO_DB.DEMO_SCH.CUSTOMER_ADDRESS ADD SEARCH OPTIMIZATION ON SUBSTRING(CA_ADDRESS_ID);
Which queries will benefit from the use of the search optimization service? (Select TWO).
Assuming all Snowflake accounts are using an Enterprise edition or higher, in which development and testing scenarios would be copying of data be required, and zero-copy cloning not be suitable? (Select TWO).
A Developer is having a performance issue with a Snowflake query. The query receives up to 10 different values for one parameter and then performs an aggregation over the majority of a fact table. It then
joins against a smaller dimension table. This parameter value is selected by the different query users when they execute it during business hours. Both the fact and dimension tables are loaded with new data in an overnight import process.
On a Small or Medium-sized virtual warehouse, the query performs slowly. Performance is acceptable on a size Large or bigger warehouse. However, there is no budget to increase costs. The Developer
needs a recommendation that does not increase compute costs to run this query.
What should the Architect recommend?
A Data Engineer is designing a near real-time ingestion pipeline for a retail company to ingest event logs into Snowflake to derive insights. A Snowflake Architect is asked to define security best practices to configure access control privileges for the data load for auto-ingest to Snowpipe.
What are the MINIMUM object privileges required for the Snowpipe user to execute Snowpipe?
An Architect has designed a data pipeline that Is receiving small CSV files from multiple sources. All of the files are landing in one location. Specific files are filtered for loading into Snowflake tables using the copy command. The loading performance is poor.
What changes can be made to Improve the data loading performance?
Consider the following COPY command which is loading data with CSV format into a Snowflake table from an internal stage through a data transformation query.

This command results in the following error:
SQL compilation error: invalid parameter 'validation_mode'
Assuming the syntax is correct, what is the cause of this error?
Which technique will efficiently ingest and consume semi-structured data for Snowflake data lake workloads?
A retailer's enterprise data organization is exploring the use of Data Vault 2.0 to model its data lake solution. A Snowflake Architect has been asked to provide recommendations for using Data Vault 2.0 on Snowflake.
What should the Architect tell the data organization? (Select TWO).
An Architect needs to design a Snowflake account and database strategy to store and analyze large amounts of structured and semi-structured data. There are many business units and departments within the company. The requirements are scalability, security, and cost efficiency.
What design should be used?
A Snowflake Architect is designing a multi-tenant application strategy for an organization in the Snowflake Data Cloud and is considering using an Account Per Tenant strategy.
Which requirements will be addressed with this approach? (Choose two.)
An Architect Is designing a data lake with Snowflake. The company has structured, semi-structured, and unstructured data. The company wants to save the data inside the data lake within the Snowflake system. The company is planning on sharing data among Its corporate branches using Snowflake data sharing.
What should be considered when sharing the unstructured data within Snowflake?
An Architect is designing a file ingestion recovery solution. The project will use an internal named stage for file storage. Currently, in the case of an ingestion failure, the Operations team must manually download the failed file and check for errors.
Which downloading method should the Architect recommend that requires the LEAST amount of operational overhead?
When using the COPY INTO
command with the CSV file format, how does the MATCH_BY_COLUMN_NAME parameter behave?
When loading data from stage using COPY INTO, what options can you specify for the ON_ERROR clause?
Is it possible for a data provider account with a Snowflake Business Critical edition to share data with an Enterprise edition data consumer account?
What transformations are supported in the below SQL statement? (Select THREE).
CREATE PIPE ... AS COPY ... FROM (...)
An Architect needs to automate the daily Import of two files from an external stage into Snowflake. One file has Parquet-formatted data, the other has CSV-formatted data.
How should the data be joined and aggregated to produce a final result set?
A company is using Snowflake in Azure in the Netherlands. The company analyst team also has data in JSON format that is stored in an Amazon S3 bucket in the AWS Singapore region that the team wants to analyze.
The Architect has been given the following requirements:
1. Provide access to frequently changing data
2. Keep egress costs to a minimum
3. Maintain low latency
How can these requirements be met with the LEAST amount of operational overhead?
Which SQL ALTER command will MAXIMIZE memory and compute resources for a Snowpark stored procedure when executed on the snowpark_opt_wh warehouse?
An Architect needs to meet a company requirement to ingest files from the company's AWS storage accounts into the company's Snowflake Google Cloud Platform (GCP) account. How can the ingestion of these files into the company's Snowflake account be initiated? (Select TWO).
Options:
Configure the client application to call the Snowpipe REST endpoint when new files have arrived in Amazon S3 storage.
Configure the client application to call the Snowpipe REST endpoint when new files have arrived in Amazon S3 Glacier storage.
Create an AWS Lambda function to call the Snowpipe REST endpoint when new files have arrived in Amazon S3 storage.
Configure AWS Simple Notification Service (SNS) to notify Snowpipe when new files have arrived in Amazon S3 storage.
Configure the client application to issue a COPY INTO